

short
- ARFBench is the first AI benchmark built entirely from real production incidents.
- GPT-5 leads all current AI models with 62.7% accuracy but falls short of domain experts at 72.7%.
- The theoretical expert oracle — which combines AI and human judgment — has an accuracy of 87.2%, setting a ceiling on what collaborative AI and human teams can achieve.
AI companies continue to promote autonomy Site Reliability Engineer Agents– Artificial intelligence that investigates production accidents instead of humans. Datadog ran the actual scale on real outages, and the best AI models can’t yet beat the engineers they’re supposed to replace.
The standard is ARFBench (Anomaly Inference Framework Standard), a joint project of Datadog and Carnegie Mellon. Created from 63 real production incidents, extracted from engineers’ Slack threads during live emergencies – 750 multiple-choice questions covering 142 monitoring metrics and 5.38 million data points, with each question manually verified. No synthetic data. There are no textbook scenarios.
“Trillions of dollars are lost each year due to system outages,” the researchers wrote. The benchmark tests whether AI can actually help change that.
“Despite the central role of such question-based analysis in incident response, it remains unclear whether modern basis models can reliably answer the types of time series questions that engineers ask in practice,” the research said.
Questions come in three levels. Level 1: Is there an anomaly in this chart? Level 2: When did it start, how serious is it, and what type?
The third level—the most difficult—requires cross-sectional reasoning: Is this schema causing the problem in the other schema? This is where artificial intelligence breaks down. GPT-5 scored only 47.5% F1 on Level III questions, a metric that penalizes models that provide answers to games by choosing the most popular category.
“Despite the central role of such question-based analysis in incident response, it remains unclear whether modern baseline models can reliably answer the types of time series questions that engineers ask in practice,” the researchers wrote.
How each model stacks up
GPT-5 leads all existing models with 62.7% accuracy, in a test where random guessing got 24.5%. Gemini 3 Pro received a rating of 58.1%. Cloud Opus 4.6: 54.8%. Claude Sonnet 4.5: 47.2%.
Domain experts recorded an accuracy of 72.7%. Lay experts — Datadog’s time series researchers who don’t have extensive monitoring experience — still came in at 69.7%.
No AI model outperformed the human baseline.
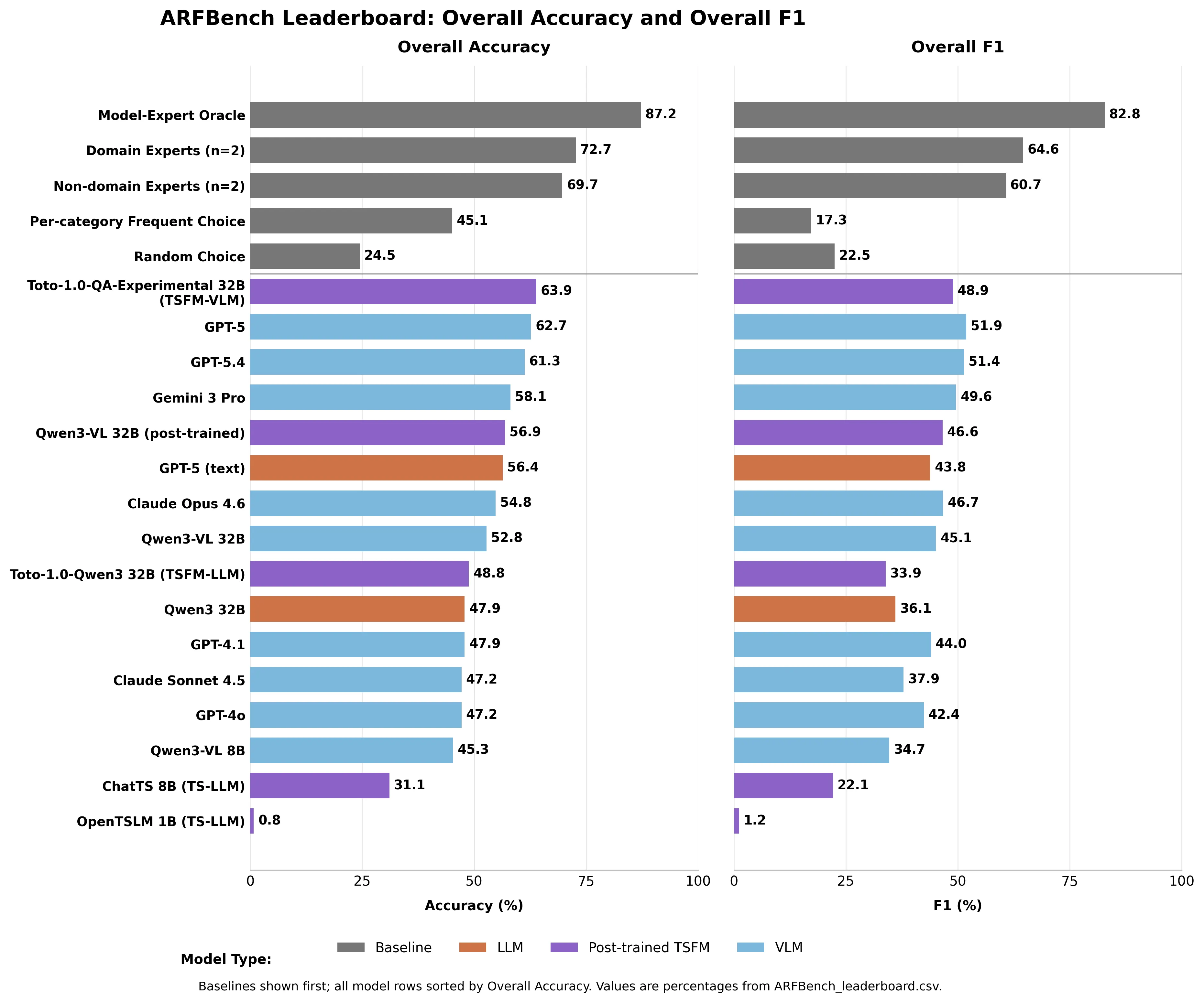
The model that topped the full leaderboard was Datadog’s hybrid model: Toto – an internal time series forecasting model – combined with Qwen3-VL 32B. Toto-1.0-QA-Experimental recorded an accuracy of 63.9%, outperforming GPT-5 while using a fraction of its parameters. In terms of identifying anomalies specifically, it outperformed all other models by at least 8.8 percentage points in Formula 1.
A purpose-built domain model, trained on observability data, outperforming a general-purpose general-purpose system on this specific task is the expected result. This is the point.
The most valuable result is not the model that received the highest results.
“We observed a significant difference in error profiles between the leading models and human experts, suggesting that their strengths are complementary,” the researchers wrote. Models hallucinate, miss metadata, and lose domain context. Humans misread precise timestamps and sometimes fail to execute complex instructions. The errors barely overlap.
Model a theoretical “Oracle-Expert” — the perfect judge who always chooses the right answer between the AI and the human — and you get 87.2% accuracy and 82.8% F1. Way over either alone.
This is not a product. It’s a Documented goal– Built on real emergencies, not curated data sets – which determines exactly how much better human-AI collaboration performs. Leaderboard live on Hugging Face. GPT-5 by 62.7%. Ceiling 87.2%.
Daily debriefing Newsletter
Start each day with the latest news, plus original features, podcasts, videos and more.



