

short
- DeepReinforce released Ornith-1.0 on June 25 under the MIT License, and is specifically designed for AI coding agents working in real edge and repository environments.
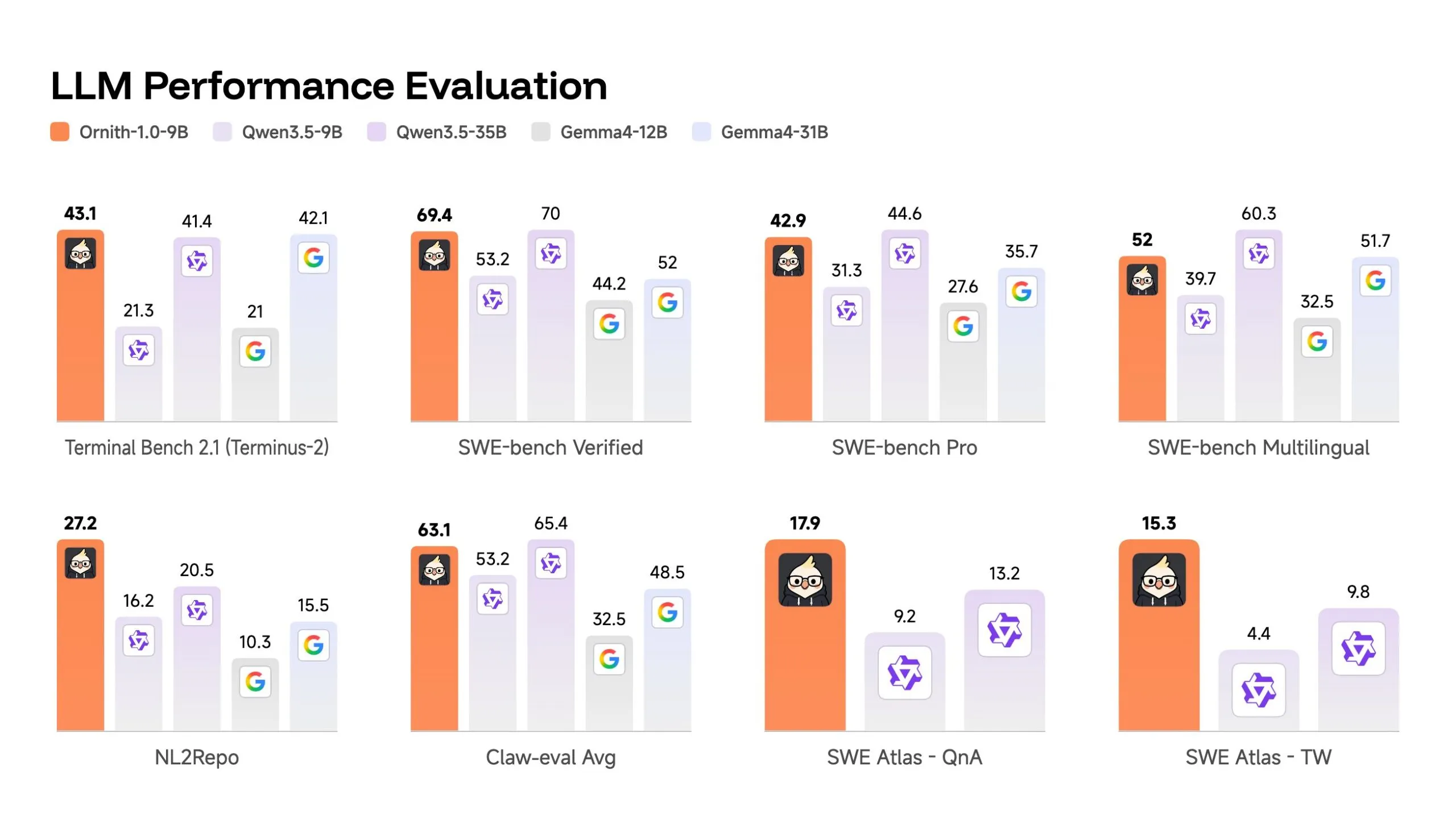
- The 9B version scored 69.4 points in the SWE-bench test, besting Google’s Gemma 4-31B (52.0).
- Ornith’s model card warns that models may perform poorly on non-coding tasks, as they are connected to developer pipelines, not general-purpose AI conversations.
DeepReinforce, formerly known as Artificial Intelligence Research Laboratory KODA-L1 and the IterX code agent optimization loop, Released Ornith-1.0 late last week – A set of open source coding models is available on Hugging Face in four sizes based on the number of parameters: 9B, 31B, 35B Mix of Experts, and 397B Mix of Leading Experts, all under the MIT license without any regional restrictions.
The parameters are basically the number of faces and configurations that the model can handle during its training. The more parameters there are, the more powerful the model is. The model with 9 billion parameters is small and good enough to run on a good smartphone, but it is unable to do any heavy reasoning task reliably. The 397B model is much more capable, but requires some heavy computing, the kind not found in consumer devices.
Laboratory describes It is “a set of self-improving open source models specifically for agent programming tasks.” This word – agent – does a lot of work.
Aloha! 🌺 Meet Ornith-1.0, a family of open source LLMs specializing in proxy coding.
The Ornith-1.0 spans full parameter sizes including 9B Dense, 31B Dense, 35B MoE, and 397B MoE. It achieves cutting-edge performance among similarly sized open source models on… pic.twitter.com/7g1rmacLps
– Ornith (@ornith_) June 25, 2026
Most of the AI people interact with is conversational: you type, it responds, and the exchange is over. Amnesty International agent It’s different, he gets a task and takes action to complete it without a human guiding each step. In the context of programming, this means artificial intelligence that reads files, runs tests, determines what failed, fixes the code, and iterates again until it is finished.
So Agentic AI means no one has to be at the keyboard most of the time. That’s the point. This is also the direction in which the most commercially significant progress will occur in 2026 – models that can run unsupervised through a 20-step development workflow are worth more than those that write clean functionality on demand.
However, most large language models are still designed with human feedback in mind.
How does Ornith’s brain work?
Most AI coding agents are paired with a human-designed tool, a fixed set of rules for how the agent structures its work: when to call a tool, how to handle an error, and how to analyze a multi-step problem. Instead Orneth “treats scaffolding as something that can be learned and evolves with politics.”
Translation: Instead of inheriting someone else’s playbook, it develops its own.
During reinforcement learning, each training step takes place in two stages. The model first reads the task and suggests a revised strategy for dealing with it. He then uses that strategy to find a solution.
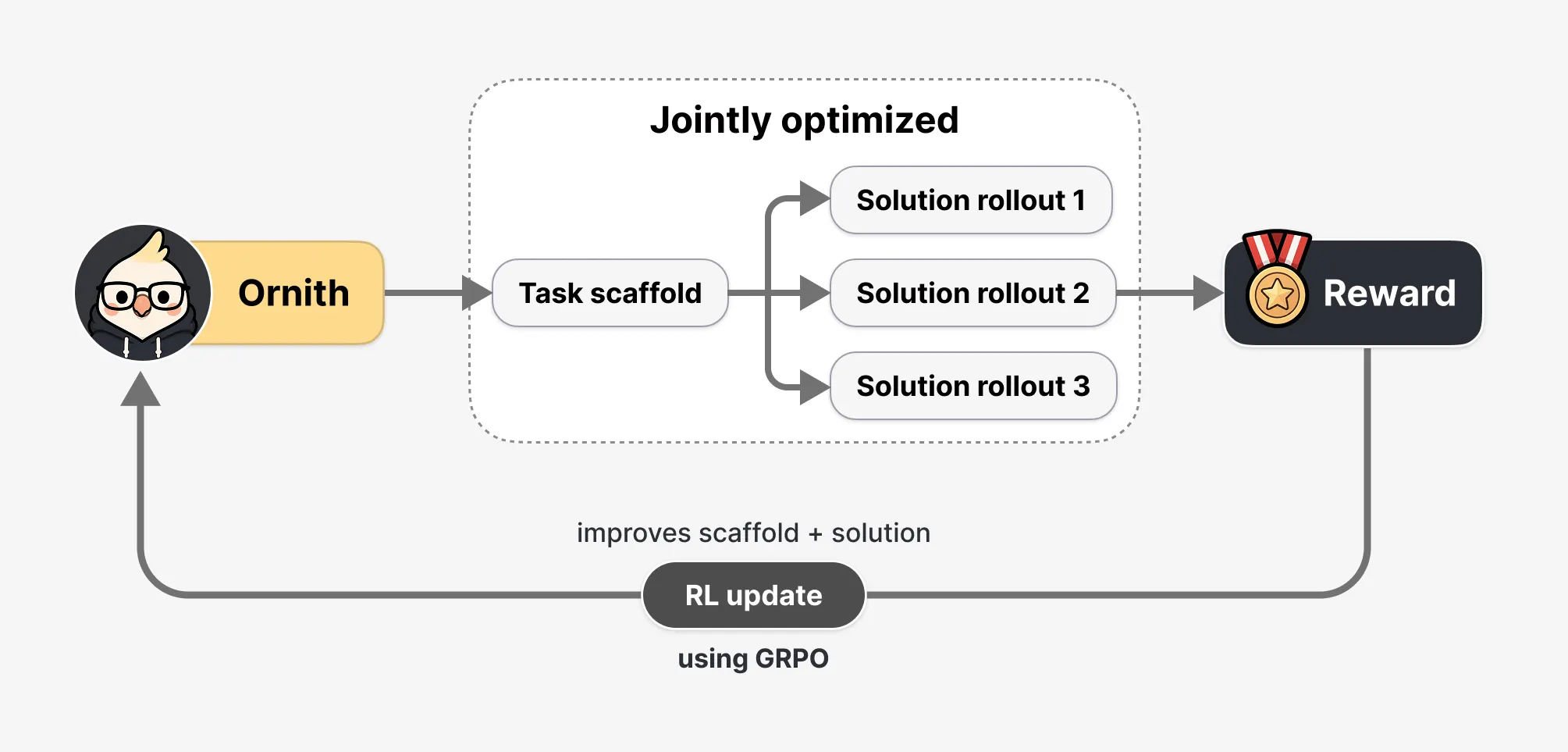
The reward from the outcome flows to both stages, so the model has been improved to write better strategies, not just better code. Do this thousands and millions of times, and specific approaches to tasks emerge without human engineering.
DeepReinforce also takes bounty hacking seriously. If the model is able to write its own training scaffold, it can theoretically write one that manipulates the auditor – touching the file to make it appear as if it has completed a task without actually doing the work. There are three layers of defense that prevent this: the environment and the test suite are immutable and outside the model’s reach, a deterministic monitor flags any attempt to access restricted paths or change verification scripts, and a frozen judge model sits above the automated verification tool as a veto.
Numbers
The 397 billion key parameter model deploys 82.4 in the SWE-bench — a test in which the AI is given a real bug from an open source GitHub repository and must fix it without seeing the test suite, and is scored as a percentage of the problems it successfully solves.
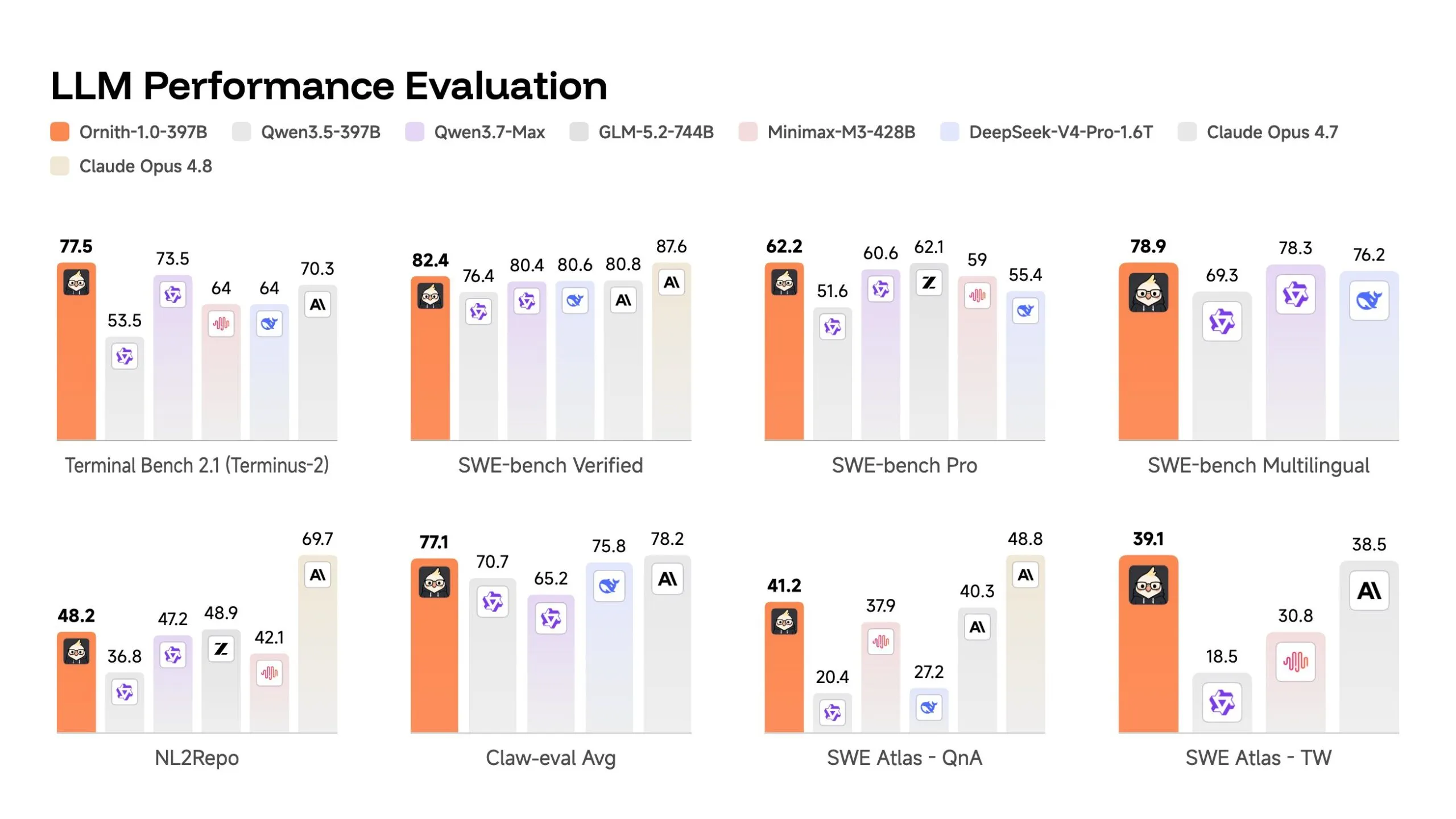
This beats the Claude Opus 4.7, which scored 80.8, and the DeepSeek-V4-Pro, which scored 80.6, in the same test. In Terminal Bench 2.1—89 tasks run within containerized terminal environments ranging from debugging asynchronous code to resolving security vulnerabilities, which are scored by completion rate—scoring 77.5 versus 70.3 for Claude Opus 4.7.
On condition Contamination concerns SWE-bench It went public — OpenAI argued earlier this year that models were inflating results by memorizing benchmark solutions seen during training — and Ornith also reported numbers for SWE-bench Pro, a harder version that uses a more diverse, less leaky codebase and scored in the same way. The 397 billion model is up to 62.2 there. Much less, but still competitive in this area, and still better than the Deepseek V4 Pro.
A 9 billion data point parameter model would be more interesting. It scored 69.4 on SWE-bench Verified – higher than the Gemma 4-31B’s 52 and competitive with the Qwen 3.5-35B’s 70, despite being 3-4 times smaller.
Who is this for, and who is not
Ornith-1.0 is clearly not a general-purpose AI. The documentation for the model says it may perform poorly on tasks outside the scope of proxy encryption. If you want AI to summarize a document, help you write your doctoral thesis, or draft an email, Ornith-1.0 is the wrong choice.
It is optimized for a limited set of problems: development pipelines where an AI agent takes a task description, runs within a code repository or terminal session, and completes multi-step work without intervention. This tool is designed for people who actually run agent infrastructure, not for people trying to decide if AI is worth using.
The headline “beats Claude” is true but requires context. like Decryption has been reportedEvery tester now chases performance through proxy coding evaluations, because that’s where the useful performance differences live.
The Ornith-1.0-397B outperforms the Claude Opus 4.7 on both different encoding benchmarks, but Anthropic’s current flagship, the Claude Opus 4.8, scores higher. The comparison performed falls into the category of open source, with comparable parameter numbers, in cryptographic proxy tasks.
For developers building self-hosted pipelines, proxy infrastructure, or similar programming-focused businesses, small and medium models that run on high-end hardware can be really useful, but the average Joe might be better looking elsewhere.
Daily debriefing Newsletter
Start each day with the latest news, plus original features, podcasts, videos and more.


