

short
- Google has released DiffusionGemma, a free, open-weight model that generates full blocks of 256 tokens simultaneously via text propagation, reaching over 1,000 tokens per second on the NVIDIA H100, which is four times faster than standard auto-regression models.
- The custom syntax module that DiffusionGemma needs for local inference does not exist in any public runtime yet – not in mlx-lm, not in LM Studio – making it effectively inoperable in most consumer setups today.
- In NVIDIA NIM, the model arrived preconfigured at 8,192 context tokens — less than the 64,000 minimum required by agent frameworks like Hermes Agent — meaning standalone workflows wouldn’t work without manual reconfiguration.
Google dropped DiffusionGemma todayan open AI model that generates text in the same way image generators create images: start with noise, and refine it until it makes sense. Up to 1000 icons per second on NVIDIA H100. (Tokens are the basic unit of information that an AI model handles.) This means it is four times faster than regular Gemma. It’s also free, Apache 2.0, with weights on Hugging Face.
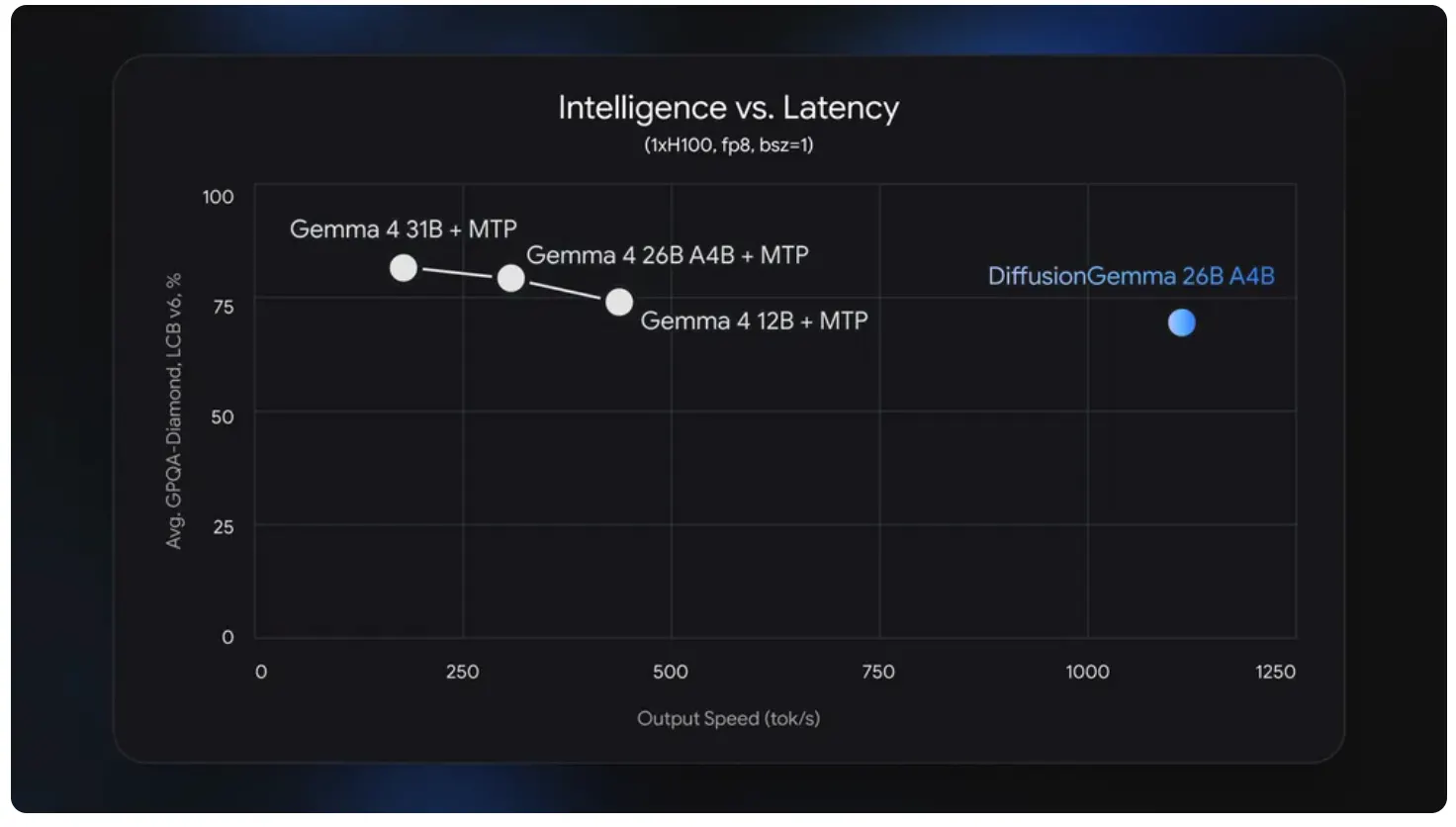
The problem, as always, is in the finer details. per Google Adthe model reaches “700+ tokens per second on NVIDIA GeForce RTX 5090.” It also trails the Gemma 4 standard in output quality.
Google says so themselves. This is an example of speed, not a quality upgrade.
What this actually does
Every LLM I’ve used is a typewriter. One symbol at a time where each word depends on the last. This is how autoregressive constructs work.
DiffusionGemma doesn’t do that. Instead of creating tokens sequentially, it starts with redacted pieces of distorted text in parallel. Per Google Developer guide“starts with a panel of random placeholder tokens” and iteratively locks placeholder tokens until the entire block is in focus. Two hundred and fifty-six tokens per forward pass. The GPU stays busy.

A side effect is bidirectional attention – each token can see every other token as it is created, which is impossible in autoregressive models (they cannot see the future, what will be encrypted). This makes it extraordinarily good at tasks where the end of the answer constrains the beginning: code filling, structured output, problems with heavy constraints, and so on. Google has set up a Sudoku solution as a demo. The basic model got about 0% of the puzzles right.
The rate of the modified version reached 80%.
Publishing the text has been a research project for years. MDLM, seat, Lada, dream– Academic models that demonstrated that the approach worked on small scales and mostly remained proof of concepts. Foundation laboratories have been shipped Mercury 2 In February 2026 as the first inference model for commercial deployment, it claimed speeds five times faster than competitors with improved speed.
But none of it was open-weight, and none of it came with zero-day support in vLLM, Hugging Face Transformers, and Unsloth. DiffusionGemma is the first major open release from a tier 1 lab.
There is also an anachronism worth noting. Image generators started out as diffusion models (hence the name Stable Diffusion) and are now moving towards autoregressive architectures to improve quality. Linguistic models started out as autoregressive models, and now they experiment with diffusion for speed.
Why running hurts…for now
Running DiffusionGemma efficiently requires a drafter – a lightweight module that proposes code blocks in parallel, which the main model then verifies in a single forward pass. This is called speculative decryption. CDFlash It is a framework published in early 2026 that uses a small publishing model as an editor, allowing More than 6x speedup In some tasks. It is the engine that makes this class of models practical.
Issue: DiffusionGemma needs a specific drafting tool to run locally via MLX — Apple’s machine learning framework for Apple Silicon. This module is not present in any public release of mlx-lm, in any open pull request, or in the LM Studio compiled runtime.
We tried running DiffusionGemma with Hermes through NVIDIA NIM. The form loaded, but then: “Agent init failed: The form google/diffusiongemma-26b-a4b-contains a context window of 8,192 tokens, which is less than the minimum 64,000 required by the Hermes agent.”
To be precise: DiffusionGemma’s actual context window is 256k tokens. The 8,192 number was Nvidia screwing things up by default, not the architectural limit of the model.
In practice, configuring it properly for agent use requires manual work that most regular users have not yet discovered, and the Hermes Agent would not be able to configure without it. Parallel speed means nothing if the proxy can’t boot.
Hopefully, in the next few days, the community will produce better resources to run these models.
Who is this actually for?
Developers using NVIDIA RTX 4090 or 5090 hardware build real-time tools — built-in editing tools, auto-completion, code filling, and structured generation. This is the goal. Also decrypt Covered in MayGoogle has been striving to make local inference faster without new hardware.
For researchers, bidirectional generation opens up an area that autoregressive models simply cannot access, such as protein sequences, mathematical graphs, and anything where the N position depends on the N+50 position. This is no small thing.
Google Gemma 4 was launched under Apache 2.0 In April, DiffusionGemma continues that strategy. There is already a draft of llama.cpp PR open as of today. When the toolchain catches up, it reaches a much broader audience.
On a machine with a capable discrete GPU, 1000 tokens per second is realistic.
Daily debriefing Newsletter
Start each day with the latest news, plus original features, podcasts, videos and more.



